Htmldate: Find the Publication Date of Web Pages¶




Find original and updated publication dates of any web page. It is often not possible to do it using just the URL or the server response.
On the command-line or with Python, all the steps needed from web page download to HTML parsing, scraping, and text analysis are included.
The package is used in production on millions of documents and integrated into thousands of projects.
In a nutshell¶
With Python:
>>> from htmldate import find_date
>>> find_date('http://blog.python.org/2016/12/python-360-is-now-available.html')
'2016-12-23'
On the command-line:
$ htmldate -u http://blog.python.org/2016/12/python-360-is-now-available.html
'2016-12-23'
Features¶
Multilingual, robust and efficient (used in production on millions of documents)
URLs, HTML files, or HTML trees are given as input (includes batch processing)
Output as string in any date format (defaults to ISO 8601 YMD)
Detection of both original and updated dates
Compatible with Python 3.10 and later
htmldate can examine markup and text. It provides the following ways to date an HTML document:
Markup in header: Common patterns are used to identify relevant elements (e.g.
linkandmetaelements) including Open Graph protocol attributes and a large number of CMS idiosyncrasiesHTML code: The whole document is then searched for structural markers:
abbrortimeelements and a series of attributes (e.g.postmetadata)Bare HTML content: Heuristics are run on text and markup:
in
fastmode the HTML page is cleaned and precise patterns are targetedin
extensivemode all potential dates are collected and a disambiguation algorithm determines the most probable one
The output is thoroughly verified in terms of plausibility and adequateness. If a valid date has been found the library outputs a date string corresponding to either the last update or the original publishing statement (the default), in the desired format.
Markup-based extraction is multilingual by nature, text-based refinements for better coverage currently support English, French, German, Indonesian and Turkish.
Installation¶
Main package¶
This Python package is tested on Linux, macOS and Windows systems; it is compatible with Python 3.10 upwards. It is available on the package repository PyPI and can notably be installed with pip or pipenv:
$ pip install htmldate
$ pip install --upgrade htmldate # to make sure you have the latest version
$ pip install git+https://github.com/adbar/htmldate.git # latest available code (see build status above)
The last version to support Python 3.6 and 3.7 is htmldate==1.8.1; for Python 3.8 and 3.9 use the 1.9.x series.
Optional¶
The additional library cchardet (or its fork faust-cchardet) can be installed for better execution speed. They may not work on all platforms and have thus been singled out although installation is recommended:
$ pip install htmldate[speed] # install with additional functionality
You can also install or update the packages separately, htmldate will detect which ones are present on your system and opt for the best available combination.
The dateparser package is noticeably slower in its latest versions, version 1.1.2 is recommended for speed.
For infos on dependency management of Python packages see this discussion thread.
With Python¶
find_date¶
In case the web page features easily readable metadata in the header, the extraction is straightforward. A more advanced analysis of the document structure is sometimes needed:
>>> from htmldate import find_date
>>> find_date('http://blog.python.org/2016/12/python-360-is-now-available.html')
# DEBUG analyzing: <h2 class="date-header"><span>Friday, December 23, 2016</span></h2>
# DEBUG result: 2016-12-23
'2016-12-23'
htmldate can resort to a guess based on a complete screening of the document (extensive_search parameter) which can be deactivated:
>>> find_date('https://creativecommons.org/about/')
'2017-08-11' # may change
>>> find_date('https://creativecommons.org/about/', extensive_search=False)
>>>
Already parsed HTML (that is a LXML tree object):
# simple HTML document as string
>>> htmldoc = '<html><body><span class="entry-date">July 12th, 2016</span></body></html>'
>>> find_date(htmldoc)
'2016-07-12'
# parsed LXML tree
>>> from lxml import html
>>> mytree = html.fromstring('<html><body><span class="entry-date">July 12th, 2016</span></body></html>')
>>> find_date(mytree)
'2016-07-12'
Output format¶
Change the output to a format known to Python’s datetime module, the default being %Y-%m-%d:
>>> find_date('https://www.gnu.org/licenses/gpl-3.0.en.html', outputformat='%d %B %Y')
'18 November 2016' # may change
Original vs. updated dates¶
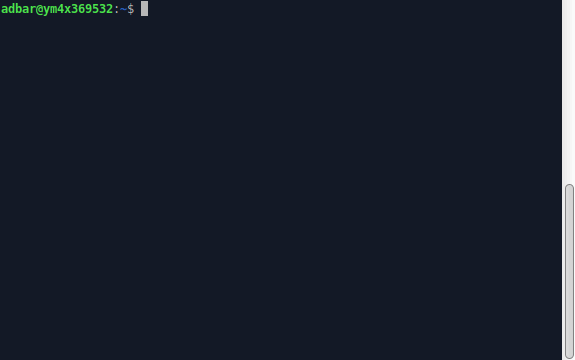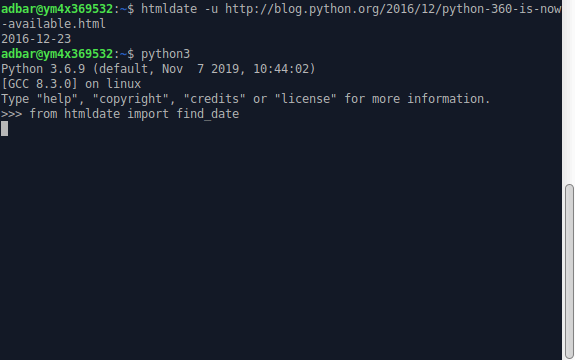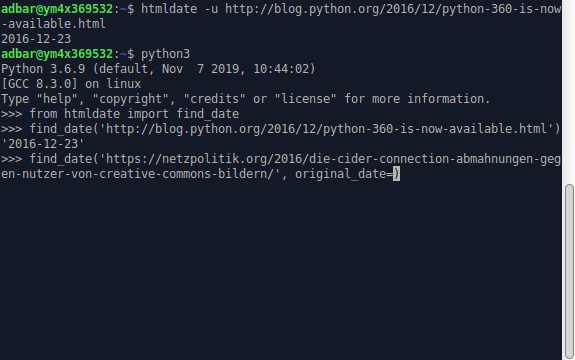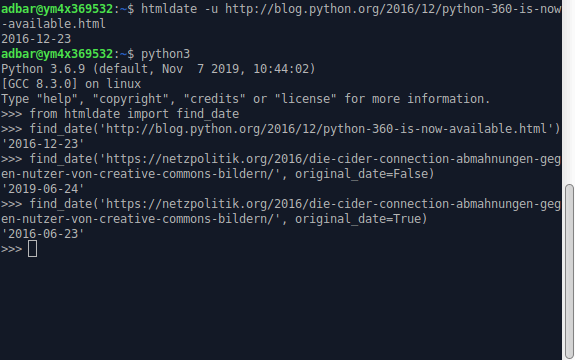
Although the time delta between original publication and “last modified” info is usually a matter of hours or days, it can be useful to prioritize the original publication date:
>>> find_date('https://netzpolitik.org/2016/die-cider-connection-abmahnungen-gegen-nutzer-von-creative-commons-bildern/', original_date=True) # modified behavior
'2016-06-23' # may change
For more information see options page.
On the command-line¶
A command-line interface is included:
$ htmldate -u http://blog.python.org/2016/12/python-360-is-now-available.html
'2016-12-23'
$ wget -qO- "http://blog.python.org/2016/12/python-360-is-now-available.html" | htmldate
'2016-12-23'
For usage instructions see htmldate -h:
$ htmldate --help
htmldate [-h] [-f] [-i INPUTFILE] [--original] [-min MINDATE] [-max MAXDATE] [-u URL] [-v] [--version]
optional arguments:
-h, --help show this help message and exit
-f, --fast fast mode: disable extensive search
-i INPUTFILE, --inputfile INPUTFILE
name of input file for batch processing (similar to wget -i)
--original original date prioritized
-min MINDATE, --mindate MINDATE
earliest acceptable date (ISO 8601 YMD)
-max MAXDATE, --maxdate MAXDATE
latest acceptable date (ISO 8601 YMD)
-u URL, --URL URL custom URL download
-v, --verbose increase output verbosity
--version show version information and exit
The batch mode -i takes one URL per line as input and returns one result per line in tab-separated format:
$ htmldate --fast -i list-of-urls.txt
License¶
This package is distributed under the Apache 2.0 license.
Versions prior to v1.8.0 are under GPLv3+ license.
Context and contributions¶
Initially launched to create text databases for research purposes at the Berlin-Brandenburg Academy of Sciences (DWDS and ZDL units), this project continues to be maintained but its future development depends on community support.
If you value this software or depend on it for your product, consider sponsoring it and contributing to its codebase. Your support on GitHub or ko-fi.com will help maintain and enhance this package. Visit the Contributing page for more information.
Reach out via the software repository or the contact page for inquiries, collaborations, or feedback.
@article{barbaresi-2020-htmldate,
title = {{htmldate: A Python package to extract publication dates from web pages}},
author = "Barbaresi, Adrien",
journal = "Journal of Open Source Software",
volume = 5,
number = 51,
pages = 2439,
url = {https://doi.org/10.21105/joss.02439},
publisher = {The Open Journal},
year = 2020,
}
Barbaresi, A. “htmldate: A Python package to extract publication dates from web pages”, Journal of Open Source Software, 5(51), 2439, 2020. DOI: 10.21105/joss.02439
Barbaresi, A. “Generic Web Content Extraction with Open-Source Software”, Proceedings of KONVENS 2019, Kaleidoscope Abstracts, 2019.
Barbaresi, A. “Efficient construction of metadata-enhanced web corpora”, Proceedings of the 10th Web as Corpus Workshop (WAC-X), 2016.
Going further¶
Known caveats¶
The granularity may not always match the desired output format. If only information about the year could be found and the chosen date format requires to output a month and a day, the result is ‘padded’ to be located at the middle of the year, in that case the 1st of January.
Besides, there are pages for which no date can be found, ever:
>>> r = requests.get('https://example.com')
>>> htmldate.find_date(r.text)
>>>
If the date is nowhere to be found, it might be worth considering carbon dating the web page, however this is computationally expensive. In addition, datefinder features pattern-based date extraction for texts written in English.